Core Pandas Data Structures¶
Today we will only focus on the two fundamental structures:
- Series
- DataFrames
The structures we won't have time to explore are Panels, which should be explored when you're ready to do so.
Here are some key ideas behind the data structures provided by Pandas:
- data may be heterogeneous
- when data is numeric, convenience functions exist to provide aggregate statistical operations (
min(),max(),cumsum(),median(),mode(), etc.),
- data structures are decomposable and composable, that is making DataFrames from Series or Series from DataFrame is supported natively,
- data structures are translatable, that is you can create NumPy
NDArray.
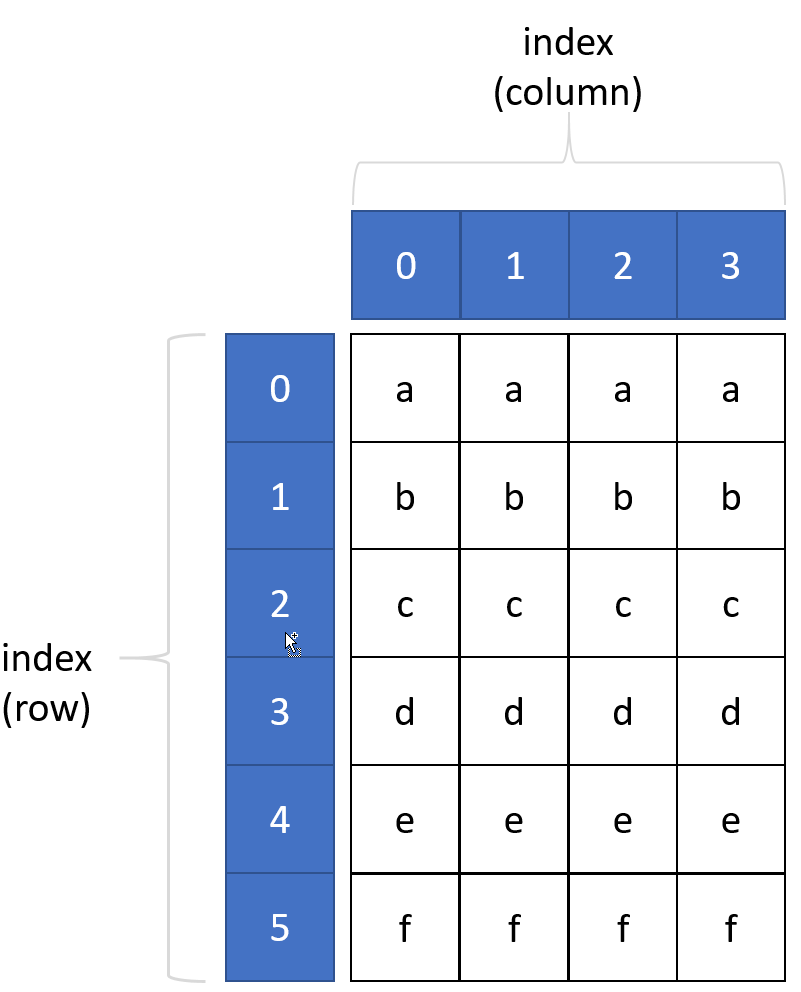
Let's play ...¶
import numpy as np
import pandas as pd
np_ints = np.random.randint(0,51,10)
pd.Series(np_ints)
Data in a series do not have to be numeric:
import string
random_letters = [''
.join([string.ascii_letters[c] for c in np.random.randint(0,51,10)])
for i in range(10)]
pd.Series(random_letters)
We can specify an index if we'd like that will allow us to have meaningful labels to access the data in the Series:
index = ['city', 'state', 'zip', 'neigborhood', 'area_code']
data = ['Denver', 'CO', '80023', 'Furhman', '303']
s = pd.Series(data, index)
s
Now we can access the data by its index label ...
s['city'], s['state']
Accessing data in a series is much like accessing data in a Python list. The usual slicing operator is available to get at the data in the Series.
s[1]
s[0:3]
s[0:3:2]
More sophisticated slicing by index using integers can be achieved with iloc. Here are some simple examples:
s.iloc[0:3]
s.iloc[0:3:2]
We can pass a list of the indices we'd like just as easily ...
s.iloc[[1,2,4]]
To get at all the values of the Series as an NDArray, simply do
s.values
which then allows us to convert to a list
s.values.tolist()
DataFrames¶
DataFrames are a natural extension to Series in that they are 2-dimensional, and similarly to matrices (from vectors). They have many of the same operations (extended to 2 dimensions), but have some additional properties and operations.
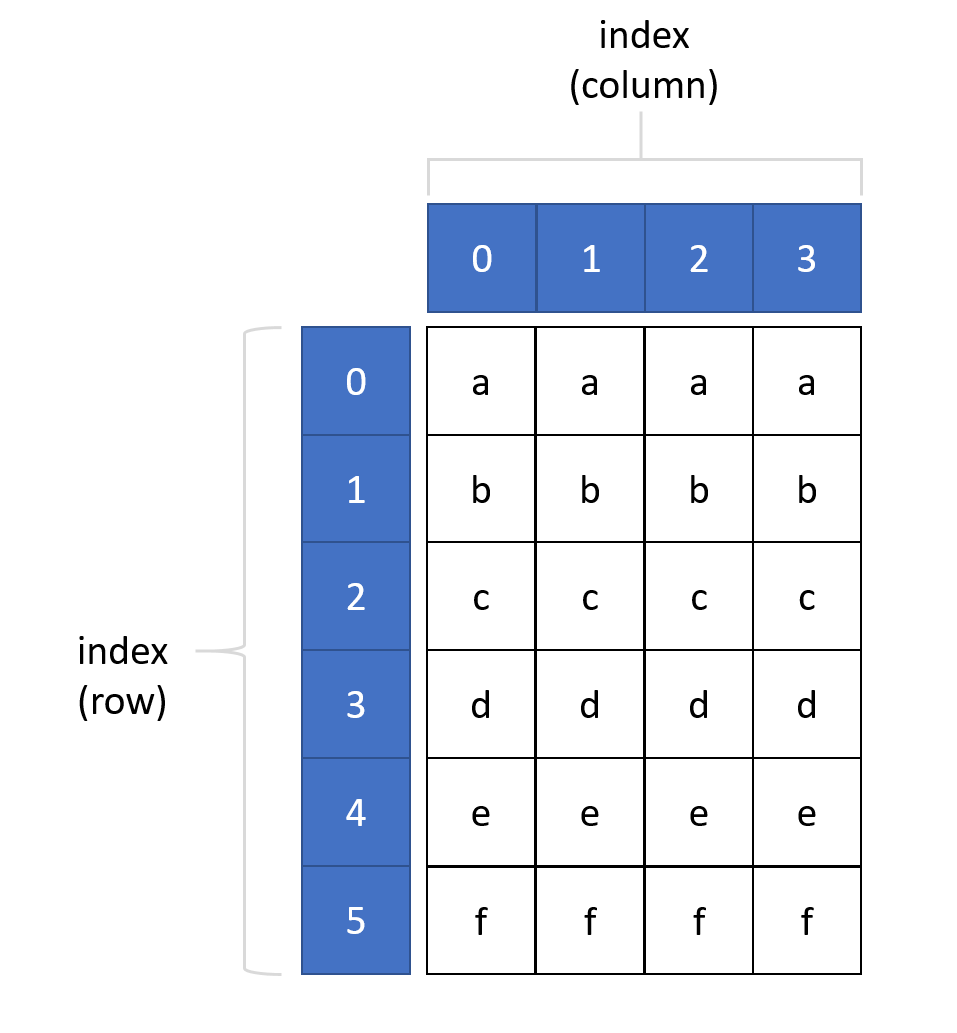
We'll cover the basics here:
- a DataFrame has a row and column axis, which defaults to numeric values (0 and 1),
- a DataFrame axis can be multi-level, that is multi-level indices can be created for row, column or both,
- DataFrames can be converted to
NDArrayand thus be converted to lists and dictionaries, - indexing is achieved either by integer value or index label (both where applicable),
- DataFrame values may be heterogeous.
Let's first begin by building a DataFrame from a 2D Numpy array ...
df = pd.DataFrame(np.random.randint(1,100,100).reshape(10,10))
df
[] operator for basic slicing¶
- the slicing operator
[]works on DataFrames over row slices.
- this operator sparingly it is not consistent with
locandiloc, and may create confusing code if mixed arbitrarily with those selectors
df[1:4] # selecting the rows index 1 to 4
df[0:4][1] # selecting rows index 0 to 4, column index 1
df[1] # selecting column 1, rows 0 .. n
df[1][4] # selecting the value at row index 4, column index 1
iloc[]¶
ilocis an integer-based selector. As such, you will need to know the integer values of the row or column indices as necessary
- you may see some correspondence with the
[]selector, but it provides much more
df.iloc[1] # row index 1, returns the full ROW
df.iloc[1,2] # row index 1, column index 2
df.iloc[1,:] # row index 1, as above
df.iloc[1,2:4] # row index 2, column index 2:3
df.iloc[1:2,:] # row index 1:2, column index 0:-1 same as above
More sophisticated slicing¶
More sophisticated slicing can be done over integer indices. For example, if we wanted specific rows and columns for slicing.
Just remember,
- the first argument to the selector is the row
- and the second, the column
df.iloc[1:2,2:5] # row index 1:2, column index 2:5
df.iloc[[1,3,7], [2,5,6]] # row indices 1,3,7 column indices 2,5,6
loc()¶
loc() is a label-based selector, and provides a much richer experience in selecting data.
- it improves the overall readibility of analysis code and also
- it allows for multi-indices to become more easily understood
df_si = pd.DataFrame(df.values,
index=['r{}'.format(i) for i in range(0,10)],
columns=['c{}'.format(i) for i in range(0,10)])
df_si
Selecting contiguous slices (indices are sorted), is very straightforward.
df_si.loc['r3':'r4',]
As expected we can slice the columns as well.
df_si.loc['r3':'r4', 'c2':'c3']
... on to Part II: Importing Data.